

这一章会系统介绍游戏的优化,如果检测性能问题。
全盘的优化方法
并行技术和全局方法
优化的开始我们需要找到瓶颈,如果优化的方向错了 会导致我们的优化完全无效
最大的性能提升在系统层面
过去在编译器优化上做的努力往往在硬件优化面前都是苍白无力的。
编译器每18年可以让算力翻一倍。
但是cpu的玛丽每年增长60%,而编译器则只有4%
所以在系统层面处理的时候要确保你使用了所有你可以用的东西。
而作为游戏开发者你要在最差的机器上测试,这样意味着你的游戏可以在所有的机器上跑。
处理过程
在前面的章节我们说了整个优化流程,这里我们会讲得更细
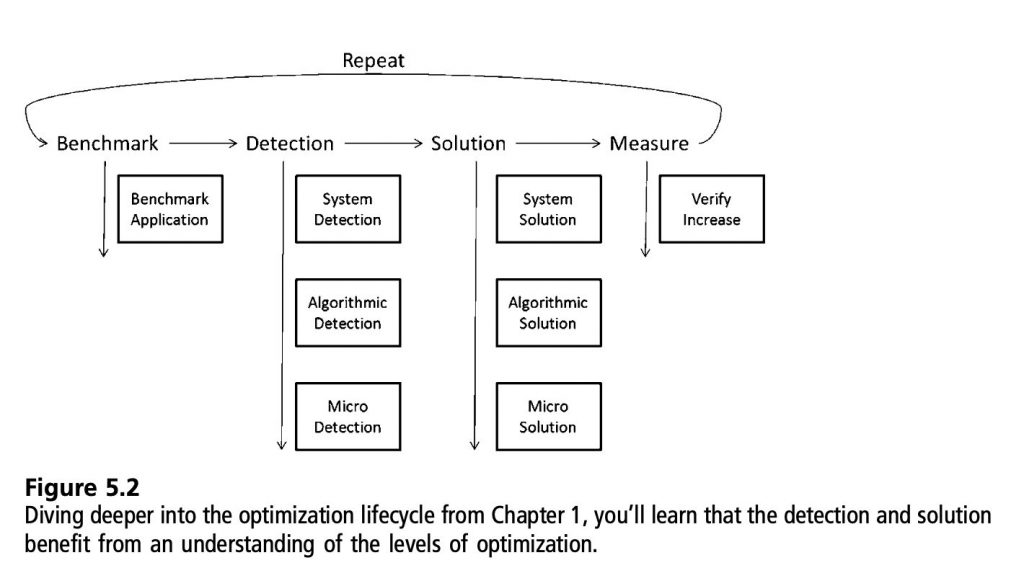
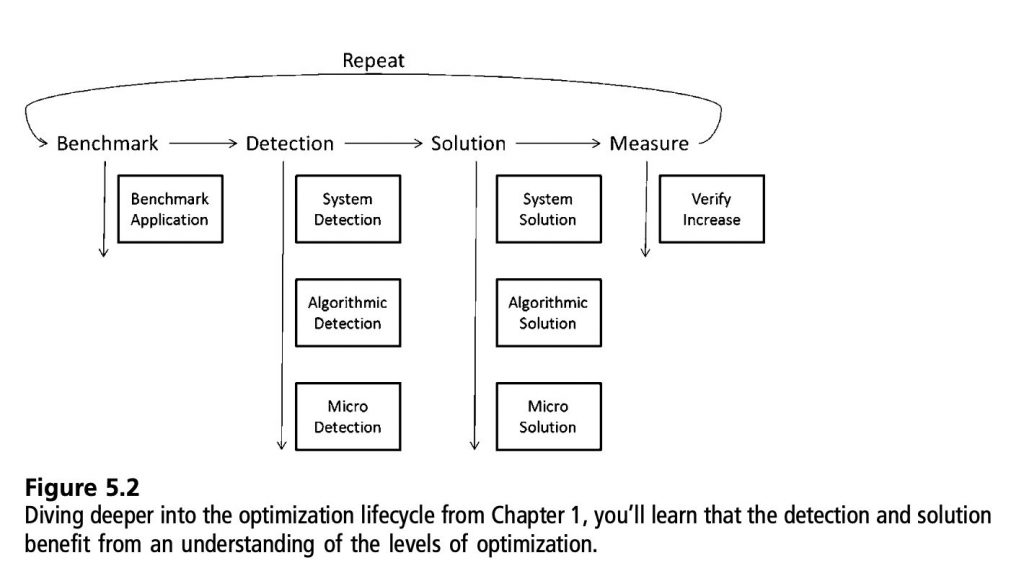
- 首先是benchmark,可重复的测量方案。
- 检测,查找最大的优化机会以及ROI,通过你的分析工具。从系统层面、算法层面到微观层面,每一个层面你都要集中到一个瓶颈。
- 进入解决方案流程,例如CPU动画系统由于过多的骨骼导致太多的举证计算,你可以把这个问题分成三个阶段:
- 系统:CPU是限制的资源
- 算法:太多的矩阵和顶点交互
- 微观:太多的加发、乘法、内存fetching
- 系统:将动画移到GPU
- 算法:不要对影响很小的顶点进行矩阵运算
- 微观:把加法、乘法使用SSE指令,然后通过fetch内存来更缓存友好
- 无论你使用了哪种优化方法,最后度需要进行测量来验证改进你需要重复以上步骤来进一步优化性能。
Benchmark
选择好的benchmark
在项目开始的时候可以选择适当的场景进行模拟。但是不要过度专注于一个子系统,这会导致瓶颈转移到另外的系统。
GPU利用率
性能模板分到两块:CPU和GPU
GPU的利用率取决于CPU,但是反过来不是这样的。
如果你在等待GPU,。有可能你使用API的方法没有面向性能。
如果你的GPU利用率很高,那么command buffer也许很满。CPU跑太前面到之后后面需要等GPU处理完之后才能再处理后面的CPU命令,导致卡顿。
另一个性能问题可能由于GPU等待数据导致,也就是带宽不足。
CPU也会等待GPU的情况。锁Z-buffer,在处理遮挡处理的时候,CPU等待Z-buffer数据返回。
另外两个Command Buffer的因素:如果说Command Buffer队列很满,那么我们需要等待GPU消耗完这些Command Buffer。另外一个是如果GPU的管线很深,那么我们需要等待所有线性阶段执行完之后才能flush来获取Z-buffer信息。
优化方向
确定CPU和GPU的利用率能够才有正确的优化方向并且需要使用不同的优化技术。
可以先创建一个GPU Bound的应用,然后慢慢增加CPU工作,当帧率下降的时候就到达CPU和GPU平衡的时候。
工具
使用显卡商提供的工具。可以帮助你查看GPU压力。
CPU Bound:总览
如果确定是CPU Bound,可以使用profiler了。这个时候分两种情况,有源码和没源码的情况。如果有源码那就方便了,各种都工具都能用,如果没有的话看看有没有符号表,如果足够幸运的话吗,是否有工具内置在模块中。
大部分游戏开发中最常见的就是图形API。
你能解决所有以上问题的就是更好得使用API,查看最耗时的执行路径。
CPU 源码Bound
当CPU遇到源码bound的时候,应用程序一般有三种导致缓慢的情况:
- 计算本身
- 内存
- 指令获取
需要的东西
在处理bound问题的时候不要过于匆忙,先找准位置,有时候问题比你想象得更简单。
多思考宏观方向:系统、算法、微观。
是否可以把计算从CPU挪到GPU?算法是否满足多线程?是否有更好的LOD手段?如果快到deadline可以尝试一些微观优化。
一般来说瓶颈总在你期望的地方,物理、AI、粒子系统,或者任何你做了大量计算的地方。不要被容易优化的地方遮蔽了眼睛。有时候你的性能就被缓慢的OS调用或者bug吃掉了。
工具
通过VTune可以得到热点的位置,测量cache miss的情况。你也可以用vtune确定指令fetch的问题。
CYCLES_L1I_MEM_STALLED/CPU_CLK_UNHALTED.CORE的值很高的话表示工作集的指令过大,以至于cache无法更高效使用。
第三方模块bound
如果你的限制在第三方模块你会有一些蛋疼的地方。你没源码你看不到哪里有性能损失。
那优化人员怎么做?小心检查并且使用一些trick。
PIX可以用于查看API call。如果没有PIX的工具只能注释出关键代码跟踪具体发生的事情。然后与项目代码分离,测试性能变化。
理解API非常重要,所以阅读相关文档非常重要,比如DX的SDK文档。否则你永远没法知道。
正确的使用API和使用API不出错是差别很大的两个事情。
GPU Bound
使用统一shader架构(Unified Shader Architecture)的显卡,分享他们的多核处理器用于顶点、几何、像素着色器。
Pre-Unified Shader Architecture
shader model3.0把显卡分成两个部分:像素和顶点。虽然两边多核,但是任意一边出现瓶颈都会导致性能无法提升。有时候通过测试可以查看哪边对性能更有效。
把分辨率调低,如果帧率上去了,那瓶颈在像素,否则在顶点。
工具
使用PerfHUD,你可以设置剪刀矩形
Unified Shader Architecture
shader 模型4.0有顶点、几何、像素shader,但是大部分SM4的显卡有统一架构。也就是说这些所有的shader跑在相同的shader核心上面。所以在SM4硬件上会把所有的shader操作作为统一的性能指标。
工具
如果不依赖硬件的话是很难测量shader核心性能的。
PerfHUD可以获取这个信息。使用性能面板,你可以测量shader利用率。还能看出是哪种shader上出现的瓶颈。
核心
确定你是填充限制还是几何限制。获取到足够信息之后将会让你的瓶颈马上显现出来。
最好获取数据的方法是从尾到头进行一系列的测试。这需要大量的工作来完成。有时候需要修改应用程序的可视化内容。不过这样可以让你了解你的时间去哪里了。在测试的时候观察帧率变化,排除潜在的性能瓶颈。
因为显卡工作就像流水线。从系统层面来看,如果你降低管线内核的工作负载但是性能并没得到提升,那么说明瓶颈并不在你的内核上。
每个管线的阶段做不同的任务,每个阶段都有自己的解决方案。下面我们会讨论更多细节。
在GPU中进行平衡
放你写了一个单线程的3d光栅化。你会发现图形管线就是很多的嵌套循环。伪代码可能向下面:
foreach( draw call )
{
// triangle creation
foreach( triangle )
{
// pixel creation
foreach( pixel )
{
// shade & blend into framebuffer
}
}
}
我们可以看到更多的pixel shader会比三角面片渲染调用。所以一般在pixel shader上面的优化会更加有效。
如果你换一种模式,如果三角面或者drawcall比pixel多的话很快就会有大量的问题出现。因为pixelshading的设置大量的浪费。
不同的渲染模式使用不同的方式处理这个情况。基于tile的光栅化会在绘制pixel之前排序。在不同的平台上要保证你确实了解GPU做了啥操作。
片元剔除
图形管线把基本图元转换到了屏幕空间用于光栅化。在早期的时候可以有机会丢弃无用的信息,来减少屏幕绘制。
在几何处理之后,光栅化单元将三角面转换为图元,在这个阶段,硬件可以剔除不可见的图元。
AMD称作Hiz,NVIDIA称作ZCULL。
另一个片元剔除的机会在运行shader之前,这是逐像素的节省有价值的像素计算资源。GPU尝试各种方法来避免运行不需要的shader。
通过将不透明物件从近到远渲染,你可以保证最近的深度会被写入。排序可能引入消耗,但是如果你有比较好的场景图,就可以将消耗降到最低。
有个最终的trick你可以使用,你相信将场景渲染两次比渲染一次更快吗。
EarlyZ Culling需要两趟渲染,第一趟颜色写入禁用,只写入深度。第二趟关闭深度写入(不清理深度信息),再进行颜色写入。这主要利用了深度写入不需要复杂的颜色计算。
第二pass中使用之前存下来的Z信息,你可以只绘制已经初始化好的深度的颜色。
这个可以让像素遮挡剔除非常高效。这个是一个权衡的优化,因为它会引入比较多的drawcall。但是你不需要多次设置像素shader。如果你的drawcall和vertex消耗比较低,而你的pixel消耗比较高,那么pre-pass是一个比较好的优化选择。否则排序渲染就足够了。
图形总线
一般你正常使用图形API是不会引起问题的,但是如果你用了过时的图形总线,或者你用了错误的API方式。
如果用完了显存,显存和非本地内存的swap会出现。这种处理好过crash但是会带来大量的消耗。
在检查GPU的时候往往需要使用排除法,如果GPU bound没有被任何的GPU核心占用,那么最后我们可以推断bus。排除法比较简单,但是比较花时间。