

优秀美术基于shader之上。好的美术总是需要的,但是好的shader可以让好的美术发光。你可以找到大量的相关资料。
在这个章节,我们会探索不同的Shader性能的因素,以及如何检测并修复在shader中的瓶颈。为了达到这个目的,我们用两大章做铺垫。
不同的显卡都有不同的性能特点,如果你需要知道卡的特点,你需要针对特定场景跑测试。所以这里只用GTX260来跑,大部分的显卡可以按类似的规律来单还是要记住一切以测量为前提。
要一直记住优化的宏观情况。你的shader可以优化到消耗更少的时间,但是你的游戏场景复杂度有更大的性能影响。在开始优化之前要确定你花的时间在正确的方向上。
Shader Assembly
就像C++这样的高级语言映射到会标,shader也是映射到汇编。
看一下最小的例子:

你可以看到shader汇编给你很多细节来看背后到底执行了什么。你可以看一些关于背后发生了什么的有趣细节。举个例子对于输出颜色有一个专用寄存器,oC0,然后条件语句直接通过汇编实现。
对于更复杂的shader,你可以快速从汇编中看出HLSL到底在背后做了什么。虽然shader编译器变得越来约好,有时候一个小的上层shader变化会导致底层汇编结果大不一样。了解shader到底做了什么总是非常值得的。编译的输出结果包含了指令数以及其他的信息。
使用fxc
With the DirectX SDK, a tool called fxc is available to compile your shaders from the command line. fxc can be found in the bin folder of the DirectX SDK. It has many uses, but most significantly, you can use it to get an approximate idea of the complexity of the shaders you are running. The command line to generate the example in Figure 10.1 is simple: fxc /T ps_3_0 /E RenderScenePS BasicHLSL.fx Of course, fxc /? will give you full information on all its arguments, but a quick summary is as follows: /T ps_3_0 Specifies the shader model to target, in this case, a SM3.0 pixel shader. /E RenderScenePSSpecifies the entry point for the shader, the function at which to start execution. BasicHLSL.fx The most important argument is the FX file to compile, of course. fxc has many other features commonly found in compilers. You can have it print the source lines that correspond to a given block of assembly. You can have it emit debugging information or optimize more or less aggressively, too. There are many other fancier and nicer tools out there, but in many situations fxc is all you need.
Full CIrcle
在这一点上你可以回去看看Memory和Compute这两章。当我们讨论优化CPU代码的时候,GPU改变宏观性能的时候,一旦你深入到Shader层,CPU的优化技巧又可以重新拿出来说事。
主要的CPU和GPU的区别是GPU用于大量的并行。内存获取是非常严格的,程序非常小并且独立,这样所有的实例可以并行执行。至少当使用DX和OpenGL,程序只在特定上下文执行,移除了大量的bookkeep overhea以及基础设施,用户有的时候需要自己去实现。
你可以在GPU上跑通用计算(后面会讲到的GPGPU)。如果你使用了,很多限制会出现,更通用的计算模型可以使用。大部分情况下这不是一个好的选择,针对3D渲染的应用来说,因为它带来了比表面渲染更复杂的计算。(当前这是10年前的情况)
找到你的瓶颈
在知道我们的GPU是瓶颈之后,我们需要确定GPU管线的哪个部分是你的瓶颈。永远要确定瓶颈之后再进行优化。
快速回顾,你可以通过降低像素的数量来确定是否是pixel shader瓶颈,你可以通过降低顶点数量来确定你的vertex shader是否是你的瓶颈。然后降低你的曲面细分来测试你的几何shader是否是瓶颈。你需要依次测试这三个,因为管线的顺序是先从pixel再从vertex再到geometry。
一旦你怀疑GPU的pipeline瓶颈了,下一步是剥离消耗时间的特定shader来决定你如何来优化它。下面从不同的方面来说明不同的优化方向和方法。
Memory
像CPU一样GPU也会被内存访问拖慢。GPU的优势是有成百上千的并行单元。所以在获取数据的时候有更多的机会去做有用的事情。第九章说了一些memory的指导意见,比如降低顶点和pixel的尺寸可以提高缓存友好性。Vetex和Texture的格式也有助于缓存的友好。
简单思考一下每种shader怎么和内存交互。我总得来看shader model4 。越低级的shader model有更多的限制。
- 几何shader通过一组几何数据来生成更多新的几何
- 顶点shader输入一个vertex 输出一个vertex
- 像素shader输入插值属性,基于三角面,输出颜色值混合到framebuffer
额外的基于支持的shader model所有的shader类型你可以获得不同的数据,比如现在的硬件上面可以从vertex或者甚至是几何shader上采样texture
shader内数据交流
不同shader之间共享的数据可能会影响性能,不过只影响某些方面。trade-off就只有时间换空间。传递属性像UV或者法线,所有的资源。如果他们能够打包更紧密,使用更少的属性,可以获取部分性能,这个不仅仅是性能问题,如果你有大量的属性,这也值得一试。
贴图采样
贴图采样是内存访问最大的问题。如果一不小心,可能会导致主要的性能问题。两个主要的因素影响shader性能:采样的数量以及深度依赖。我们在上一章中讨论了改变采样数的方法,我们重新用shader实现了这个例子:
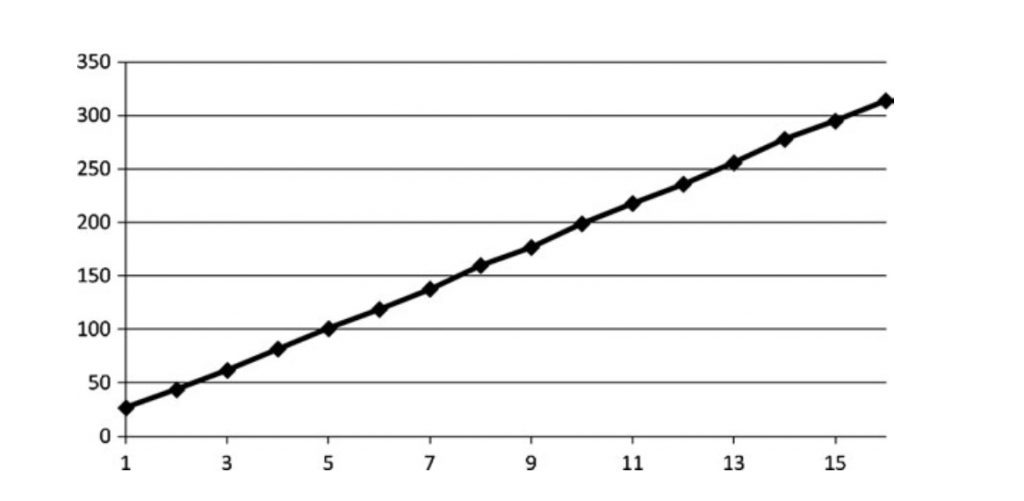
深度读取依赖是目前最复杂的问题。它就像第六章我们提到的数据依赖,它会造成从VRAM fetch贴图数据,加上filtering的overhead。下面是一个测试:
float4 read1 = tex2D(sampler1, texCoord1);
float4 read2 = tex2D(sampler1, read1.xy);
float4 read3 = tex2D(sampler2, read2.xy + float2(0.2, 0.2)); float4 read4 = tex2D(sampler2, texCoord2);
这个采样有四个贴图读取,从下面的图我们可以看到依赖读取的影响
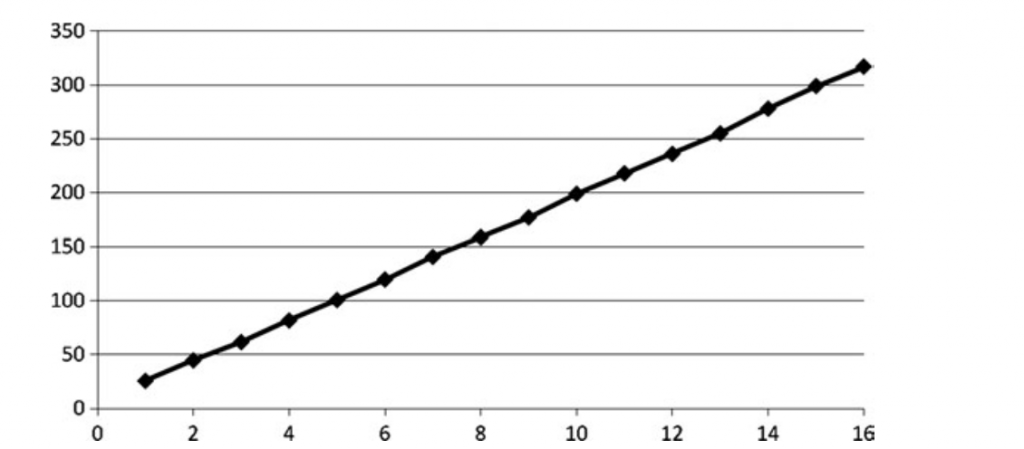
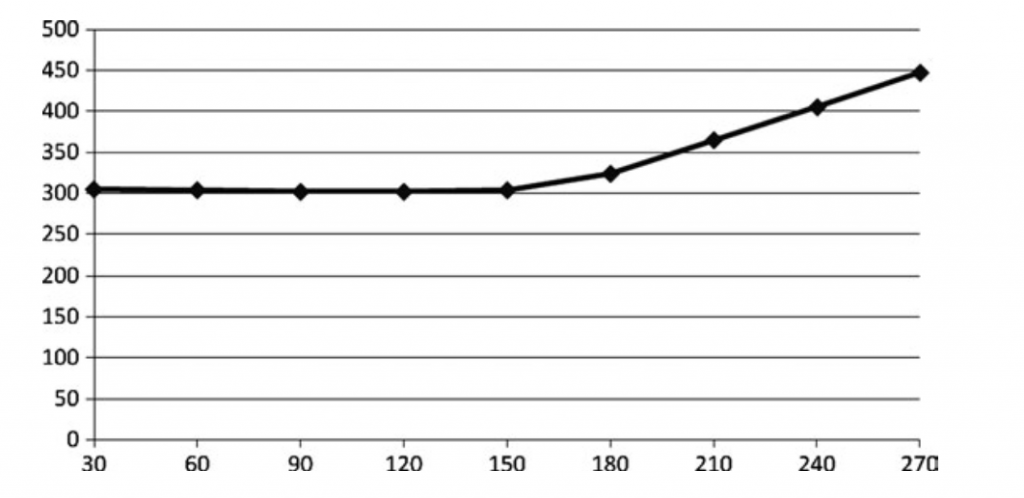
对于很多效果,依赖读取是必要的。如果做一个BRDF查找表,基于法线来查具体的值。在这种情况下如果性能问题,这个解决方法不能避免所有的问题,但是尝试填补由于依赖读取造成的延迟空洞是一个不错的方法。花100的周期的时间采样一个贴图,在这个例子中,假设没有编译器优化会花400个周期去结束所有的贴图采样,加上read3两个float相加的耗时。
shader编译器会更聪明,会记录你的代码所以会在read3计算之前fetch read2。帮助隐藏read1的延迟。降低3ms左右的耗时。
如果你有大量的数学计算不依赖于read2和read3,编译器会自动把计算提前来隐藏延迟。然后等所有加载计算结束之后可以无延迟地进行处理。有时候你可以做的是利用目前可以使用的性能优势,而不是降低你的footprint。
和降低Sample一样,降低贴图大小可以帮助我们定位到这个问题,有一下方法来尝试解决这个问题:
- 降低读取:无脑选项,但是这个值得看的。这个贴图是否真的是你需要读取的。你是否可以通过一些计算来取代?
- 打包数据:艺术家经常不使用alpha通东,你可以通过将一些数据放到alpha通道上面来节约第二张贴图。或者你可以储存normalmap值使用两个通道,然后使用另外两个通道来储存高光和细节贴图,而不是使用三张贴图。
- 降低带宽:就想上一章说的,贴图格式可以影响渲染使用的带宽。你使用的是16位还是32位,是否使用浮点数?他们可以快速消耗大量的带宽。
- 优化缓存:如果你经常读取像素,你或许会有cache missing。cache假设你会读取周边的cache。如果你乱序排序你会失去这个优势,导致性能下降。
GPU的buttom line非常容易读取和filtering贴图。只要稍微注意一点你就可以最大化性能。但是如果不小心,你可能把所有时间都用于等待内存,而不进行实际性的工作。
计算
你的shader也可能计算bound。
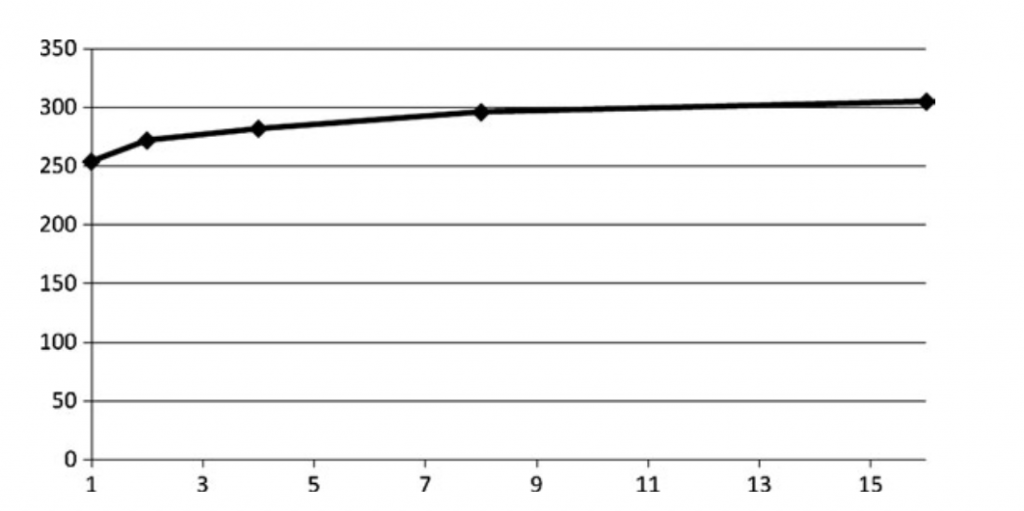
检测bound最简单的方式 是降低数学计算。下图显示shader性能与数学的相关性:
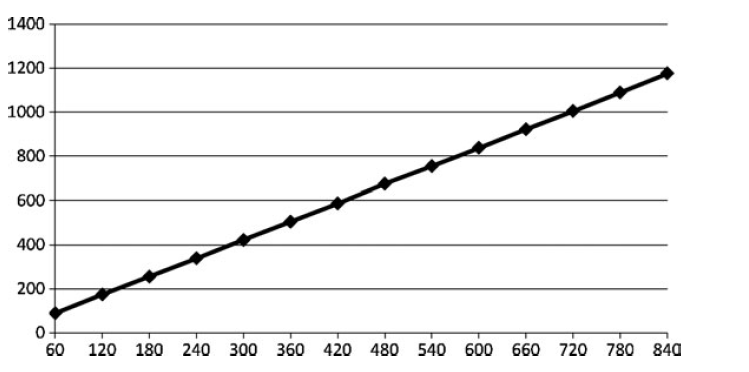
有很多方法可以降低shader中的计算。下面我们介绍一下。
隐藏延迟
贴图时高延迟的,当我们的计算依赖到贴图的时候,它们在贴图加载完之前都无法开始。保证shader编译器记录了足够多的计算来替代贴图读取的时间。在上层这意味着在tex2D调用之前移动大量的计算操作。并且需要保证没有参数依赖于贴图。也就是说我们要在指令层面更多的增加并行。
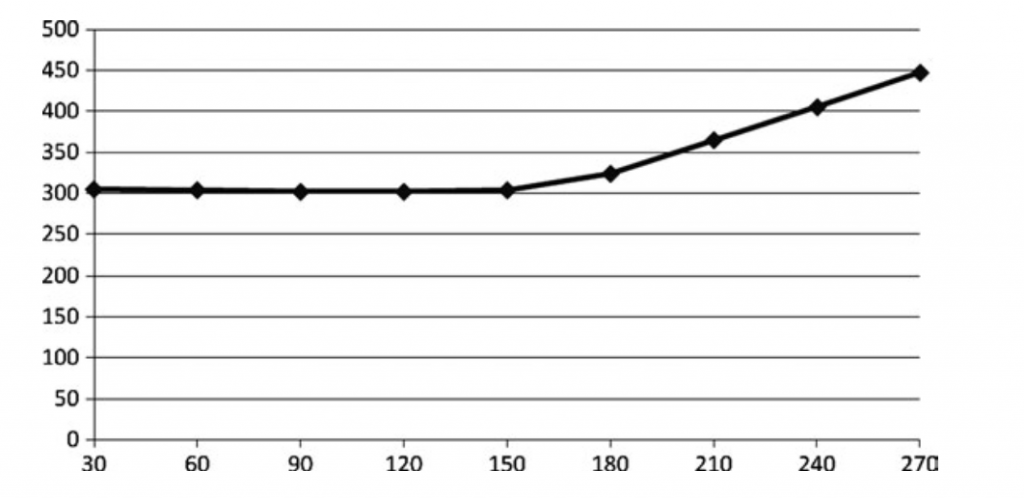
牺牲质量
或许你不需要全精度的sin或者cos在光照计算上。一个dot计算给你最够的质量范围。虽然并不是完全对齐的但是玩家一般也感觉不出来。
将shader中的一些流程提前,有些东西是否确实需要在pixel shader上面做,是否可以提前到顶点shader后插值。一些复杂的值可以直接储存在一个常量中,或者从CPU的Drawcall中获取。
空间时间Trade off
如果你有复杂的公式,比如BRDF或者光照曲线,只有很少的输入数据,可以尝试将其放入一个查找贴图。会增加一些延迟,但是如果你是计算延迟,一些计算其实可以通过fetch来获取。如果查找表足够小,它会保留在texture cache中,极大降低延迟。
有时候一个复杂的阶段可以储存在额外的贴图中。举个例子,一个irradiance贴图可以储存灯光的方向和强度。如果你的光照公式直接通过一个不依赖其他参数的数据来计算新的值,那就不应该每一帧读取计算值。或者如果你使用空间发现贴图用于静态物体,然后转换到世界坐标,直接存世界坐标的法线可以直接省去这个开销。
如果你准备从贴图获取数据,把数据移动到一块未使用的地方那完全就是免费的性能。你之前在为完全没有用到的像素消耗性能。
控制流
控制流作为重要的特性被使用在shader里面。一个循环可以在一些情况下有用,但是在性能上则不是。从编程的角度来说确实有用,但是他们需要被小心地使用。有多个for循环的shader,loop执行完之后会导致阻塞,暂停执行剩余的shader。循环让代码更容易读也更稳定,但是旧版本的HLSL必须unroll循环执行。更新的版本或许不需要。这其实由这个循环是静态还是动态决定。
下面是静态循环:
for (int i=0; i<5; i++)
Output.RGBColor = g_MeshTexture.Sample(
MeshTextureSampler,
In.TextureUV) * In.Diffuse;
生成的汇编如下:
SM2:
texld r0, t0, s0
mul r0, r0, v0
mov oC0, r0
SM3:
texld r0, v1, s0
mul r0, r0, v0
mov r1, c0.y
rep i0
mov r1, r0
endrep
mov oC0, r1
如果改成动态循环之后:
for (int i=0; i<Var; i++)
Output.RGBColor = g_MeshTexture.Sample(MeshTextureSampler, In.TextureUV) *
In.Diffuse;
生成的汇编如下:
texld r0, v1, s0
mul r0, r0, v0
220 Chapter 10 n Shaders
mov r1, c1.x
mov r2.x, c1.x
rep i0
if_lt r2.x, c0.x
add r2.x, r2.x, c1.y
mov r1, r0
endif
endrep
mov oC0, r1
正确使用分支可以加速代码,但是有一些陷阱需要避免。如果使用一些正确的操作,可以跳过剩余的shader。静态分支非常不错,因为可以在编译期做比较,或者在shader执行之间。静态分支的问题是无法做内联。动态分支,依赖于运行时变量。每次比较的时候都会有运行时的性能惩罚,性能在执行分支之后都会发生变化。需要注意的是动态分支在每一个顶点、几何、像素之前,比较操作可能增加得非常厉害。
常量
常量在DX中时非常特殊的变量。一般来说,他们是shader之前储存在寄存器或者buffer的常量,与运行时改变的变量不一样。了解API的限制不一定能显现出最优解是非常重要的。举个例子,shader model3硬件要去支持256位shader常量。大部分的架构将shader常量储存在缓存和寄存器。固定常量可能有时候会编译到shader中。但是当你超出了可用空间之后可能会出现性能断崖。
有序号的常量不一定在cache或者寄存器中申请,因为真正的值在查找index之前是不知道的。在反编译后你可以看到C0[a0.x]。反编译显示出它们在寄存器储存并不意味着它们真的在硬件寄存器上。
在D3D10中常量Buffer(CBuffer)的概念被推出。不是独立更新常量,而是把整个buffer进行更新。但是这可能和你期望的所相反,如果你有两个最常更新的常量在两个分开的cbuffer里面,你可能造成更多需要做的工作。常量应该通过更新频率来进行分组。
cbuffer UpdatePerScene
{
float Constant_1;
float Constant_2;
float3 Constant_3;
float4 Constant_4;
float4 Constant_5;
};
cbuffer UpdatePerFrame
{
float Constant_6;
float3 Constant_7;
float3 Constant_8;
float4 Constant_9;
float4x4 Constant_10;
};
在D3D9中,大部分的硬件支持商优化驱动来保证寄存器和缓存来储存合适大小的常量。在D3D10中,因为CBuffer的特性,优化任务落在了开发者身上。组织这些buffer可以优化之前提到的寄存器和cache的储存速度。
D3D10还介绍了另外一个概念:Texture Buffer(tbuffer)。类似于cbuffer,但是这是用于优化大尺寸常量的随机访问。TBuffer是一个混合包,因为他们快速增加了内存的footprint,引擎了cache miss。在低内存的硬件上面,会导致性能的快速下降,如果你怀疑这里引起了瓶颈,你可以降低常量内存使用,然后看性能是否提升。
运行时考虑
Shader为程序带来了强大的能力。但是在一些游戏的基础设施上也会受到一些影响。他们或许不会成为你profiler上的瓶颈,但是会造成你代码的复杂度和维护性的消耗。
第一个地方是shader编译。所有shader会在加载时编译成某种协议(除非你只是用单种GPU和无限制的API,类似于主机)。即使shader汇编转换成GPU的机器码。更一般的情况是,程序通过HLSL和GLSL发布,在运行时编译。这样更灵活,也更容易通过驱动更新来改进性能,但是这会花一定的时间来编译所有的shader代码。注意你的加载时间,或许可以通过组织你的shader来受益于缓存降低加载时间。
第二个地方是shader数量。早期的GPU无法同时运行多个shader,意味着你修改正在使用的shader需要flush shader执行单元。最近的GPU可以同时执行多个不同的shader了,但是你人会遭到大量shader在同一个场景里的惩罚。它造成了shader cache的紧张,意味着更多的状态切换。
有一些方法可以处理shader数量。第一个是ubershader,也就是单个shader处理非常多种情况,而通过开关打开和关闭不同的特性。有用但是会引入其他的overhead,主要是带来了难以维护的问题,以及单个shader中过多的指令数。
第二个是编程上的方法,可以在运行时通过上层材质描述把shader从多个fragment shader拼接起来。这要求大量的基础设施,而且一个错综复杂的引擎,但是你得到的是一个干净的shader。
最后,手写方法是技术美术和程序员一起针对每一个场景开发不同的shader。表面上看上去更加有效,但是实际应用中,游戏倾向于依赖更少的高质量材质。如果艺术家有一个好的把手,他们可以上世界看上去更好看。
还有其他的选项来降低shader数量。最大的shader爆炸的情况不是基础shader材质,而是光照、阴影和材质之间的交互。如果你的基础材质乘以灯光数量乘以阴影数量,你不光面对大量的shader程序的增加,而且还有shader在drawcall之间初始化的复杂度。
通过延迟管线,你可以通过相同的shader来处理所有的世界中的物体,少量的shader用于灯光和阴影的增加,最终材质的shader用于最终渲染。这降低了指数级的shader数量上涨。当然这要求更多的渲染复杂度以及填充率,所以对于简单场景和灯光或许并不值得使用。
最后,需要考虑的是特效框架。现在已经有DirectX Effects Framework,CgFX或者ColladaFX。他们通过类似于NVIDIA的FX Composer来支持。提供了高级语言来描述几何像素以及顶点shader可以被材质组合起来。非常灵活地构建复杂和模块化的材质。
然而特效框架往往面向易于使用以及灵活性,而且他们是闭源的。你会发现大部分游戏引擎UE3,Source,Unity3D,Torque,Gamebryo都有自己的材质特效渲染系统。因为管理shader和材质是性能非常重要的一环,也就导致依赖第三方库是非常糟糕的主意。他们非常tricky地把特效框架加入到渲染管线里面。他们并不总是支持所有平台,他们对于艺术家来说也很容易在性能方面引入问题通过从网页拷贝代码。
为你的游戏引入特效引擎没有什么坏处。可以通过项目的成熟阶段来选择库。建议抽象你自己的材质系统,这样你就可以自由切换特效框架,这样你就可以不需要重新写你的游戏引擎了。