

编写好的渲染代码是困难的,因为变量很多。
不需要跟进最新的系统版本、GPU或者驱动。这些因素可以大大改变你的性能大纲,如果你升级驱动之后有一个case特别慢,那你可能只能回退,或者进行大量重构。
确定受众,选择正确的渲染API以及对应的能力来支持。
你的代码能够支持对应的性能以及可伸缩、渲染特性等。
这章主要讲如何把渲染代码最大程度优化。
作为图形程序或者优化者需要灵感来进行hack。
工程生命周期和你
从项目开始到项目结束代码会有大量的修改。在项目开始的时候载入的资源没有这么多,子系统也没有完全出现性能拉满的情况。在项目末期你可能会遇到以下情况:
- 你的游戏跑在你开发游戏时候完全没上市的GPU上
- 渲染100%正确和稳定需要一些消耗的操作
- 艺术家可能在不同的物体上使用了不同的材质。导致你有大量的状态变换
- Gameplay和其他系统占满了整个CPU
工程中可能出现的问题
你没办法一次性解决所有问题:
下面列出一些常见问题
同步
同步点可以造成巨大的性能损失。GPU是一个很长的管线,一次性通过渲染指令和资源产出结果,如果有什么依赖上一个指令的输出的话你在管线中就需要进行等待来进行最终的处理。
有些状态切换会造成高额overhead。例如新的像素shader无法受益于正在处理shader的硬件,GPU需要等待老shader结束渲染之后才能加载新的shader。
比状态切换更糟糕的是回读。当你锁定资源并且读回数据的时候,数据只优化了从CPU推送到GPU的情况其他情况下效率往往都比较低。
锁定Framebuffer或者深度buffer往往造成糟糕的性能结果。不止导致管线被flush并且渲染也在读取数据的时候完全停止。如果你足够幸运驱动程序会在其他渲染进行的时候拷贝buffer并且提供给你。但是这个需要非常小心的协作,因为锁定资源的时候程序很多时候不会提交指令。
你可能在CPU上计算顶点位置,并且将他们传输到vertex buffer。如果你不小心,你可能会在buffer里面写保存临时值的代码(例如使用*=),导致一次缓慢的回读。
如果你经常锁定某些东西的话,最好是只锁一次。最小化锁的数量是比较好的做法。
能力管理
例如:能否使用网格、是否支持MSAA、多少内存可以使用等。
不同的显卡制造商对能力的支持程度都不一样。使用OpenGL或者DX的标准API你可以再大部分设备上运行你的渲染代码。
一般驱动或者硬件商提供某些错误的情况比较少。或者某些情况下使用接口非常慢。在OSX上如果你使用一个不支持的GL特性,则会切换到软件实现。
你需要一个灵活的系统来fallback到其他work-around,使用更多一般的支持,例如PS和VS以及有多少VRAM可用。帮助你更好地扩展或者更新。
资源管理
有很多游戏因为不适当的资源管理导致游玩不流畅。或许是使用过长的时间加载或者是浪费VRAM。切到全屏模式或者重置窗口尺寸或者关卡切换时导致资源泄漏。
全局顺序
渲染指令的顺序对于优秀的性能也非常重要。驱动和GPU不知道你的场景细节,只能根据你发送的指令来执行。驱动能正确处理渲染顺序但是会带来一定的overhead。
任何的计算都可以用约束条件来简化,寻找正确的渲染顺序也是一样,通过提交正确的顺序可以让你的计算大大降低。
思考渲染顺序是很重要的。例如你想渲染shadow和反射在渲染整个场景之前,你想从前往后渲染不透明物体,并且渲染透明物体从后往前。或者你想通过材质或者贴图顺序来绘制来降低状态切换。
在绘制反射的时候我们需要切换rendertarget,需要付出高昂的代码,最好是前期就解决这个问题。
测量
好的测量意味着你对你的代码又比较好的可见性。渲染器有大量变化的模块,你需要知道哪些模块正在变化,如果你看不到你每帧有太多的锁,那你就永远无法修复它。
最好的方法是给重要的操作加上Counter系统,例如锁、drawcall、state改变以及资源创建与销毁。类似于PIX与NvPerfHUD的工具可以做这些。但是机器自带的工具是更好的,因为他们总是能获取到,即使是在艺术家的电脑上。
调试
当你在调试图形代码,像是NvPerfHUD,PIX,gDEBugger,BuGLe和GLIntercept是基本的。支持annotating你的应用,添加渲染注释,方便查看信息。使用可信任的profiler,这样可以看到你的渲染热点,代码调用或者驱动模块消耗的时间。
许多工程如果没有比较好的方法来了解场景背后做了什么,那你就不能做出明智的判断,仿佛在遮着眼睛飞行。
在引擎里面也需要工具来反复确认你的场景里面有什么东西。
保证你有有意义的错误信息,并且dump了足够的信息这样你可以像艺术家或者测试者解释问题的地方。这样你可以让工作者在有限的budget下正确地工作。
管理API
作为图形开发者,第一部就是处理API,不管你用的是DX还是OpenGL。有大量的东西可以帮你简化问题,在它们成为阻碍之前。
不要假设任何事情
使用渲染API最好的方法就是不要假设任何事情。使用最小的程序集来包装你的游戏能够正常运行。
即使是今天的API有更多可靠的平常的功能,这依旧是有用的。
GL有GLUT,Direct3D有D3DX,虽然很方便但是他们的代码容易不可靠,最好还是自己写,也写不了多少代码。
更复杂的操作,例如简化Mesh,光照程序,你也许想离线运行并且储存输出而不是依赖到你的程序中。
构建正确的包装器
保证所有的基础操作都能够支持,并且只在一个且仅有一个地方支持。好处如下:
- 到时候找问题就非常好找了
- 保证你有一个正确的API调用周期
- 方便使用fallback
- 遇到硬件或者驱动问题,也很容易绕开
- 方便打印log
- 方便跨平台
状态切换
对于渲染来说状态切换是很大的一块。减少状态切换是永远的话题。你调用渲染API改变任何东西都会造成状态切换。例如延迟渲染等渲染技术就是主要为了减少状态的切换而诞生的。
有一个比较有用的trick是通过你的wrapper来避免反复修改同一个状态,API调用有廉价的也有昂贵的。即使是廉价的调用,减少反复的调用也可以有效减少驱动的工作量。跟踪每一个状态,然后只在最后设置的时候来调用API。
有些驱动也会做一样的事情。例如你改变ABAB提交到硬件,实际顺序会是AABB,减少了一半的状态切换。
DrawCall
状态切换告诉图形卡如何绘制,而Drawcall(在DX中是DrawPrimitive或者GL的glDraw)就是实际绘制的指令。一般的驱动会吧所有工作延迟到Drawcall发送的时候,降低了反复的状态切换。虽然他们还是有很高的消耗。
你在profile的时候你发现你大部分图形API的时间都被drawcall占用。大部分是因为驱动必须出队所有的命令到GPU才能渲染,所以Drawcall本身也不能说没有明显的开销。大量的Drawcall产生了可观的CPU开销。
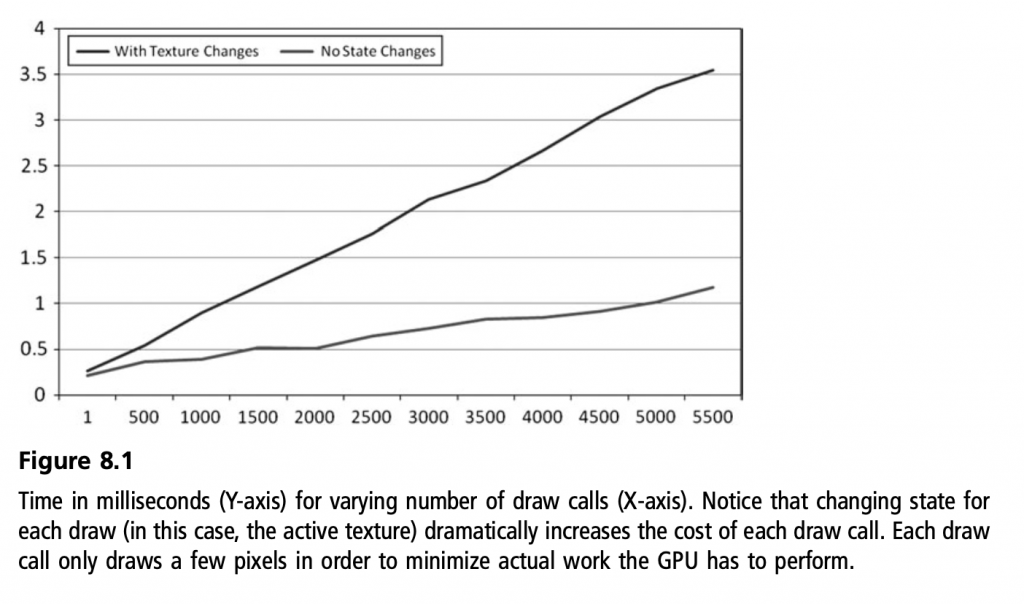
Drawcall之间如果状态切换比较大,那么消耗会比较高,看上图。一般花5ms每帧来提交drawcall比较合理。
通过工具你可以很快地找到Drawcall的瓶颈。
状态块
通过状态块,你可以把一打指令在Drawcall之间进行修改。降低GPU和驱动的工作负载。比如你可以给贴图采样器预定义状态,而不是通过大量的调用来设置,你可以注册状态快。
不同的硬件设备实现状态块的方式不一样。有的时候比较差的硬件会通过逐个设置值来模拟状态块,这个时候通过减少状态的切换可以获得更好的性能。
当然要保证所有你的目标硬件要比较好的适配,如果你的硬件不支持,驱动会计算得比你自己做更慢。
Instancing和Batching
对于大量的小物体我们可以通过将他们放入到动态的顶点buffer上来一次性绘制以减少Drawcall。但是有的时候这种方法也不够好用。
Instancing可以反复提交同一个集合体,并且使用不一样的参数。这个技术可以降低GPU提交的overhead。
有两种不同的instancing版本,也有各自的优势和劣势。
- Shader Instancing:把instancing构建放到GPU。开发者或许需要把渲染拆成好多个Drawcall。
- 硬件Instancing:硬件Instancing是shader model3.0的特性。最大的问题是需要model3.0的机器。硬件instancing使用一个数据流和一个mesh。我们可以把顶点数据map成instancing数据。不过在GPU中每个顶点也会产生overhead。
渲染管理器
渲染队列
管理VRAM
处理使用API以外管理VRAM是另一块非常重要的内容。
在渲染阶段,资源你可能申请各种各样的资源。state block、vertex或者index buffer、贴图、shader、一个活多个shader常量、一个查询或者栅栏,或者一打其他东西。下面这些时间节点比较重要:
- 设备Reset时间
- 一般渲染时
处理设备重置
设备重置在GL和DX都可能发生,但是引擎的情况不一样。基本上设备重置发生在需要丢弃所有用于渲染的东西时。在D3D可能是在改变分辨率、切换全屏、切换到其他应用程序的时候,大部分东西需要重新upload。OpenGL更好一点但是操作是相同的。
设备重置时性能很重要,比如说聊天框弹出来你不能阻碍玩家。或者进入全屏的时候要很快,不然玩家不知道发生了啥,玩家就不想玩这个游戏了。
为了处理设备重置你需要知道从设备申请的每一个资源。最简单的方法是做一个基类,这样你可以知道从设备上申请了哪些东西,并且有设备丢失的callback这样就可以在reset的时候回来进行处理。
你或许需要报错一些系统内存来重新生成内容,好在DX和GL都有比较好的文档。
资源上传与加锁
运行时是另一个资源性能重要的地方。下面是基本的守则:
- 最小化拷贝:你仅应该在需要一份和RAM上面物理上不同的数据时才进行操作。
- 最小化加锁:无论什么时候只锁一次buffer,或者连续使用或者直接解锁。
- 双buffer:你如果有频繁修改的数据,使用双buffer可以有更多的时间来处理数据,在一些情况下驱动会帮你做。
资源生命周期
确定资源的生命周期,及时回收,把资源分成以下三类:
- 每帧使用:保持一个共享的vertex/indice的buffer然后一帧中使用后清理,对性能有很大的提升。但是你如果每次绘制很少的东西可能性能会有损失。
- 动态资源:需要多帧保持的资源,但是每帧或者频繁修改。通过传入不同的flag,可以让driver更好的使用它。
- 静态资源:有些资源写入一次之后就再也不改变。通过提示驱动,驱动可以更高效地维护他们,并且更快地访问到。
小心碎片化
碎片化可以大大减少你的可用GPU内存,可以通过把所有的申请使用2次幂来减少碎片化的发生。进行一些测试,如果你的申请都是在同一个地方,可以更轻易的做这些修改。要关注那些没有被包装的API资源申请、释放调用。
其他Trick
Frame Run-Ahead
通过Frame run-ahead把绘制进行延迟。在强交互的时候你可以强制同步。
https://near.sh/articles/input/run-ahead
锁定剔除
用于Debug遮挡剔除
将整个世界锁住,然后移动摄像机查看剔除的结果。
贴图Debug技巧
通过不同颜色的Mipmap查看Mipmap分布是否合理
用checkerboard来检查对齐和采样是否正确,查找计算错误精度不足的问题。
通过渐变来查看UV分布