

来源论文:Mimalloc: Free List Sharding in Action
Mimalloc讲道理真的写的不错。
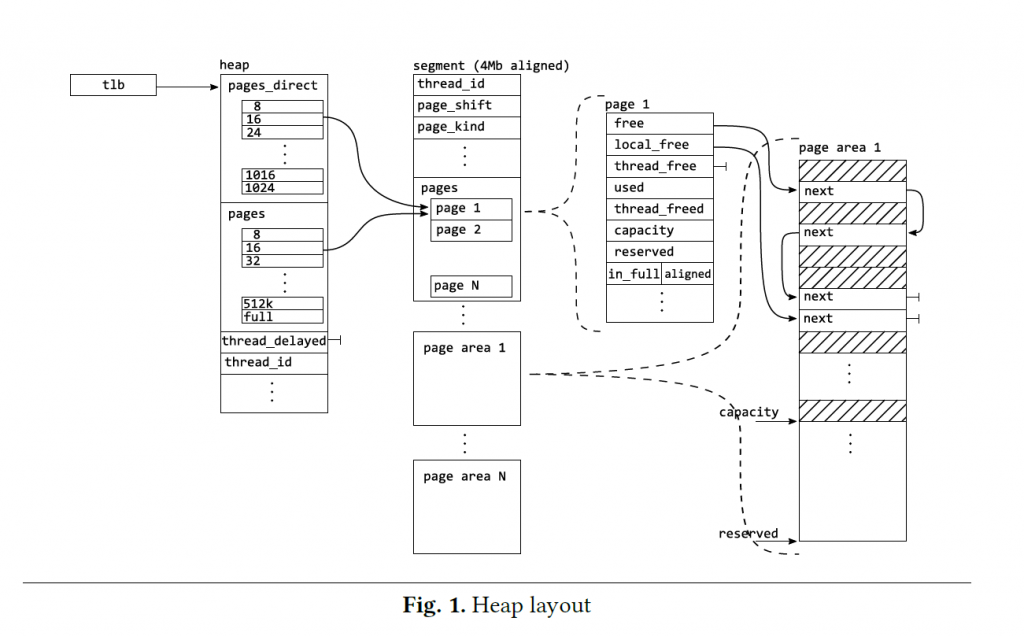
分页技术
FreeList会分成若干页,每个页有一个小的FreeList,使得FreeList有更好的空间局部性。
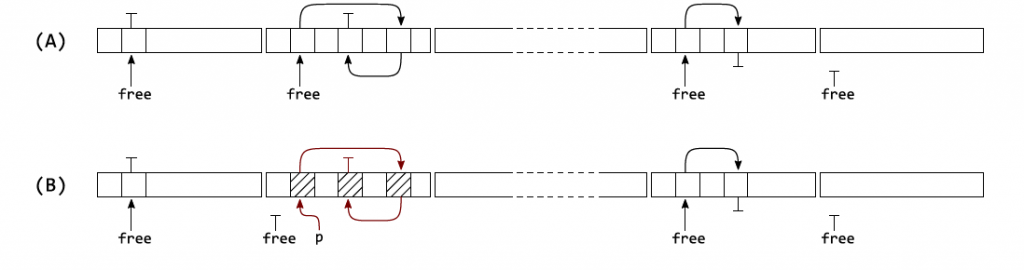
不使用指针判断
void* malloc_in_page( page_t* page, size_t size ) {
block_t* block = page->free; // page-local free list
if (block==NULL) return malloc_generic(size); // slow path
page->free = block->next;
page->used++;
return block;
}
这里只有很简单的判断来退出fast path。
很多内存申请器判断是否freelist指针指到了开头,来确定能不能分配。mimalloc通过记录一个used数量来判断。一个是减少了一次判断,而且依赖申请位置的方式并不能很好地被预测。
局部FreeList
针对频繁申请和释放的情况,我们不想频繁地进行释放操作,而是在多次申请之后进行一次释放。
当页中的本地freelist空的时候会统一进行释放,但是如果频繁申请和释放的话,本地freelist可能永远不是空的。
为此填金额了一个共享的local free list当我们从常规freelist中申请的时候我们会把释放的object丢到 local free list。这保证free list在一定的申请之后会清空。
page->free = page->local_free; // move the list
page->local_free = NULL; // and the local list is empty again
我们不需要在fast path中添加判断,而是在slow path里面去做延迟释放的操作。我们也可以做心跳来进行调用。
线程上的Free list
在mimalloc 页属于thread-local并且申请总是会在local heap中完成。这避免了撞锁。
非local的释放发生时,使用原子操作推到线程的freelist
atomic_push( &page->thread_free, p );
完整代码如下
void atomic_push( block_t** list, block_t* block ) {
do { block->next = *list; }
while (!atomic_compare_and_swap(list, block, block->next));
}
因为我们分了页,所以实际上竞态发生的情况是很少的。在没有竞争状态的情况下,原子操作非常高效。
我们使用常规调度来收集线程上的free list
tfree = atomic_swap( &page->thread_free, NULL );
append( page->free, tfree );
因为整个线程的freelist一次性move完毕,所以会把非本地的释放,一次性batch起来。这对于异步并且工作来说更高效。尽量减少了同步的次数。
申请实现

mimalloc (this link opens in a new window) by microsoft (this link opens in a new window)
mimalloc is a compact general purpose allocator with excellent performance.