

本报告描述了一个用于协同程序排序的可移植c++库。该库的功能基于编程语言SIMULA提供的协程原语。描述了该库的实现方法,并给出了应用实例。其中一个示例是面向流程的离散事件模拟库。
关键字:coroutine, simulation, backtrack programming, C++, SIMULA, control extension.
1.介绍
协程用于描述一些非协程情况下难以描述的算法的解决方案。协程提供了将程序的执行组织为几个连续进程的方法。
协程是一个具有自己活跃栈的对象,一个协程可以在一处被挂起,而执行另一个协程,稍后在其挂起的地方恢复运行。
这种形式的执行序列叫做alternation。图1.1显示了两个协程之间alternation的简单实例。
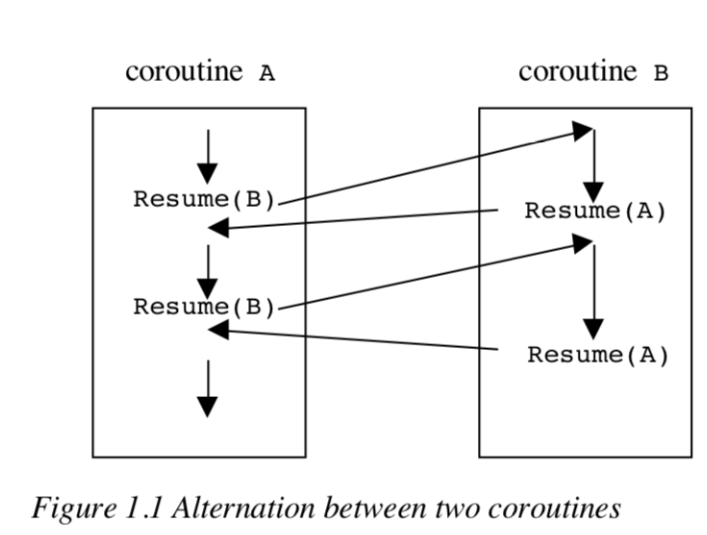
例如,协程通过多年在SIMULA中的使用已经证明了它们的有用性。一个说明性的例子是一个语法分析器调用下一个标记的词法分析器。在这里,分析程序的执行可以通过将每一个实现为一个协程来交错进行。另一个例子是离散事件模拟。这里协程可以用于过程建模,也就是物体在激活与非激活的状态下切换。
本报告描述了c++中用于协同程序排序的库。它不使用任何特定于平台的特性,并且在大多数平台上运行。该库的功能基于SIMULA编程语言提供的协程原语[2,3]。支持对称和半对称排序。
本文的其余部分组织如下。第2节给出了库的概述。它的一些使用例子在第3节中给出。其实现在第4节中进行了描述。
第5节描述了一个用于离散事件模拟的库。这个库是SIMULA内置的面向流程的离散事件模拟工具的c++实现。第6节给出了使用该库的示例。
第7节讨论了协同程序的排序和回溯编程的结合。最后,在第8节中得出了一些结论。
2.协程库
本节从用户的角度简要描述了协同程序库。
协同程序由一组协程组成,它们以准并行的方式彼此运行。每个协程都是一个具有自己执行状态的对象,因此可以暂停和恢复它。协程对象为一个函数提供执行上下文,称为例程(Routine),例程描述了协同程序的操作。
库提供了用于编写协同程序的类协同程序。协程是一个抽象类。对象可以作为实现纯虚函数例程的协程派生类的实例创建。作为创建的结果,协同程序的当前执行位置在例程的起始点初始化。
协同程序库(coroutine.h)的接口概述如下。
#ifndef Sequencing
#define Sequencing(S) { ...; S; }
class Coroutine {
protected:
virtual void Routine() = 0;
};
void Resume(Coroutine *C);
void Call(Coroutine *C);
void Detach();
Coroutine *CurrentCoroutine();
Coroutine *MainCoroutine();
#endif
控制可以通过以下两种操作之一转移到协同程序C:
Resume(C)
Call(C)
协同程序C从当前执行位置继续执行,该位置通常与它上次停止的位置相一致。当前协同程序在恢复或调用操作中被挂起,只有在随后的恢复时才能完成。
Call操作将当前协程作为C的调用者。在调用者与被调用协程中存在从属关系。C被描述为attach到其调用者之上。
当前协同程序可以通过操作将控制权让渡给它的调用者
Detach
调用者从上一次停止的地方继续执行。当前协同程序在分离操作中被挂起,只有在随后的恢复中才会完成。
函数CurrentCoroutine可用于获取指向当前正在执行的协程的指针。
与主程序对应的协程存在于程序执行的开始。这个协程的指针是通过函数MainCoroutine提供的。
下面是一个完整的协同程序。该程序显示了协同程序交替使用Resume函数,如图1.1所示。宏排序在最后一行中使用,以使主程序表现得像协同程序一样。
#include "coroutine.h"
#include <iostream.h>
Coroutine *A, *B;
class CoA : public Coroutine {
void Routine() {
cout << "A1 ";
Resume(B);
cout << "A2 ";
Resume(B);
cout << "A3 ";
} };
class CoB : public Coroutine {
void Routine() {
cout << "B1 ";
Resume(A);
cout << "B2 ";
Resume(A);
cout << "B3 ";
} };
void MainProgram() {
A = new CoA;
B = new CoB;
Resume(A);
cout << "STOP ";
}
int main() Sequencing(MainProgram())
执行此程序将产生以下(正确)输出:
A1 B1 A2 B2 A3 STOP
协同程序可以在任何时候处于四种执行状态之一:附加、分离、恢复或终止(attached, detached, resumed or terminated)。图2.1显示了协同程序可能的状态转换。
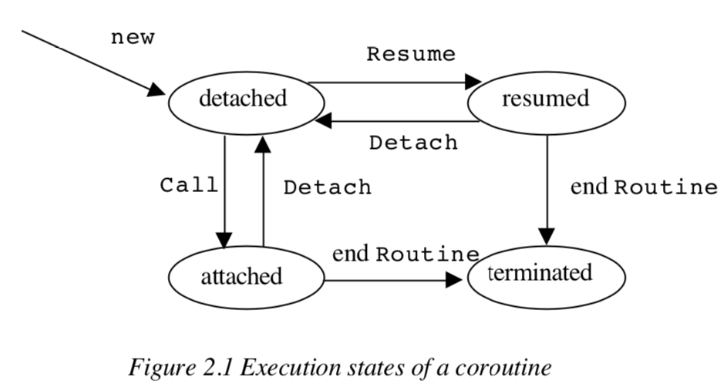
协同程序由组件组成(components)。每个组件都是一个协同程序链。组件的头部是一个分离的或恢复的协同程序。其他协同程序直接或通过其他协同程序附加到头部。
主程序对应于一个分离的协程,因此它是一个组件的头部。这个组件称为主组件。
任何时候只有一个组件是有效的。任何非工作组件都有一个相关的重新激活点,它标识了程序点,当组件被激活(通过恢复或调用)时,执行将继续执行该程序点。
调用Detach有两种情况:
- 协同程序是附加的。在这种情况下,协同程序被分离,它的执行被挂起,并在附加了协同程序的组件的重新激活点继续执行。
- 协同程序被恢复。在本例中,它的执行被挂起,并在主组件的重新激活点继续执行。
协同程序的例程函数的终止与分离调用的效果相同,只是协同程序终止,而不是分离。因此,它没有重新激活点,它失去了作为一个组件头的地位。
调用Resume(C)导致当前操作组件的执行被暂停,并在C的重新激活点继续执行。调用在以下情况下构成错误:
C 是空的 C 已经附加了 C 已经终止
调用Call (C)导致当前操作组件的执行被挂起,并在C的重新激活点继续执行。该调用在下列情况下构成错误:
C 是空的
C 已经附加
C 已经恢复
C 已经终止
一个协同程序程序只使用恢复和分离被称为使用对称(symmetric)协同程序序列。如果只使用调用和分离,则程序图使用半对称协同程序序列。在后一种情况下,协程被称为半协程(semi-coroutines)。
3.例子
3.1 简单的色子游戏
下面的程序模拟四个人玩一个简单的骰子游戏。这些玩家作为协程轮流掷骰子。第一个累计100点的玩家获胜并打印他的身份。
player对象保存在一个循环列表中。当Player-object激活时,它通过选择1到6之间的随机整数抛出色子。如果玩家对象没有获胜,它将继续循环中的下一个玩家对象。否则,它将终止,导致主程序被恢复。
#include "coroutine.h"
#include <stdlib.h>
#include <iostream.h>
class Player : public Coroutine {
public:
int Id;
Player *Next;
Player(int id) : Id(id) {}
void Routine() {
int Sum = 0;
while ((Sum += rand()%6+1) < 100)
Resume(Next);
cout << "The winner is player " << Id << endl;
}
};
void DiceGame(int Players) {
Player *FirstPlayer = new Player(1),
*p = FirstPlayer;
for (int i = 2; i <= Players; i++, p = p->Next)
p->Next = new Player(i);
p->Next = FirstPlayer;
Resume(FirstPlayer);
}
int main() Sequencing(DiceGame(4))
上面的程序使用对称协程。另外,半协程也可以使用。在下面的程序中,主程序充当主对象,玩家充当从者。主程序使用原语调用让玩家依次掷骰子。掷出骰子后,玩家通过调用Detach将控制权转移到主程序。
#include "coroutine.h"
#include <stdlib.h>
#include <iostream.h>
class Player : public Coroutine {
public:
int Sum, Id;
Player *Next;
Player(int id) : Id(id) { Sum = 0; }
void Routine() {
for (;;) {
Sum += rand()%6+1;
Detach(); }
} };
void DiceGame(int Players) {
Player *FirstPlayer = new Player(1),
*p = FirstPlayer;
for (int i = 2; i <= Players; i++, p = p->Next)
p->Next = new Player(i);
p->Next = FirstPlayer;
for (p = FirstPlayer; p->Sum < 100; p = p->Next)
Call(p);
cout << "The winner is player " << p->Id << endl;
}
int main() Sequencing(DiceGame(4))
3.2 Generation of permutations
下面所示的Permuter类可用于生成1到n之间的整数的所有排列,其中n是类构造函数的一个参数。类的对象充当半协同程序。每次调用该对象时,它都使整数数组p中的下一个置换可用。p[0],p[1]… p[n]包含排列。当所有的排列都生成后,整数成员More(最初为1)被设置为0。这些排列是使用递归函数Permute生成的。
class Permuter : public Coroutine {
public:
int N, *p, More;
Permuter(int n) : N(n) { p = new int[N+1]; }
void Permute(int k) {
if (k == 1)
Detach();
else {
Permute(k-1);
for (int i = 1; i < k; i++) {
int q = p[i]; p[i] = p[k]; p[k] = q;
Permute(k-1);
q = p[i]; p[i] = p[k]; p[k] = q;
}
}
}
void Routine() {
for (int i = 1; i <= N; i++)
p[i] = i;
More = 1;
Permute(N);
More = 0;
}
};
下面的程序使用Permuter类打印1到5之间整数的所有排列。
void PrintPermutations(int n) {
Permuter *P = new Permuter(n);
Call(P);
while (P->More) {
for (int i = 1; i <= n; i++)
cout << P->p[i] << " ";
cout << endl;
Call(P);
}
}
int main() Sequencing(PrintPermutations(5))
3.1 文字转换
…
例子有点多,就不一一列举了,直接跳到实现
4.实现
协同程序的主要特征是它的执行状态,由它当前的执行位置和一组激活记录组成。堆栈的底层元素是例程激活记录。堆栈的其余部分包含与例程触发的函数激活对应的激活记录。
当控制被转移到协同程序(通过恢复、调用或分离的方式)时,协同程序必须能够在它停止的地方继续执行。因此,在控制进入它的连续场合之间,它的执行状态必须保持不变。可以说,它的执行状态必须是“冻结”的。
当协同程序从一个执行状态转移到另一个执行状态时,它被称为上下文切换。这意味着保存挂起协同程序的执行状态,并将其替换为其他协同程序的执行状态。
实现协同程序的核心问题是如何实现这种上下文切换。目标是实现原语Enter(C)与以下语义[1]:
Enter(C)
当前正在执行的协同程序的执行点被设置为下一个要执行的语句,在此之后,这个协同程序将被挂起,而协例程C 将(重新)在它的执行点开始执行
实现了这个原语之后,就很容易实现这些原语了:恢复、调用和分离(或类似的原语)。
下面介绍了Enter的两个实现。第一个实现是基于在c++的运行时堆栈中复制堆栈。在第二个实现中,所有堆栈都驻留在运行时堆栈中(即,不复制堆栈)。
这两个实现都利用了c++库函数setjmp和longjmp的服务。
与另一种实现相比,每种实现都有优点和缺点。由于这个原因,这两个实现都可以在coroutine库的两个不同版本中使用。
没有使用特定于平台的特性。因此,这两种实现在大多数平台上无需修改即可运行。
4.1 基于栈拷贝的实现
这个实现的原理如下。
在任何时候,当前运行的协同程序的堆栈都保存在c++的运行时堆栈中。
当协同程序挂起时,运行时堆栈和当前执行位置被复制到与协同程序相关联的两个缓冲区(StackBuffer和Environment)。
协同程序通过将其堆栈缓冲区的内容复制到c++的运行时堆栈并将程序计数器设置为保存的执行位置来恢复。
标准的c++函数setjmp和longjmp用于实现上下文切换。
setjmp用于在缓冲区环境中保存当前执行状态。环境包含处理器状态的快照(寄存器值,包括程序计数器)。
longjmp用于使处理器返回到保存的状态。
setjmp将当前状态保存在缓冲区中并返回0。longjmp将处理器返回到以前的状态,就好像setjmp返回的值不是0。
下面的代码显示了类协程的接口。
class Coroutine {
friend void Resume(Coroutine *);
friend void Call(Coroutine *);
friend void Detach();
protected:
Coroutine();
~Coroutine();
virtual void Routine() = 0;
private:
void Enter();
void StoreStack();
void RestoreStack();
char *StackBuffer, *High, *Low;
size_t BufferSize;
jmp_buf Environment;
Coroutine *Caller, *Callee;
};
类的数据成员具有以下含义。
StackBuffer:指向包含运行时堆栈副本的缓冲区的指针。
High, Low:运行时堆栈的地址界限。
BufferSize:堆栈缓冲区的大小(以字节为单位)。
Environment:包含由setjmp保存的信息的数组。
Caller, Callee:附加的连接
StackBuffer、Low、High、BufferSize的含义如图4.1所示。
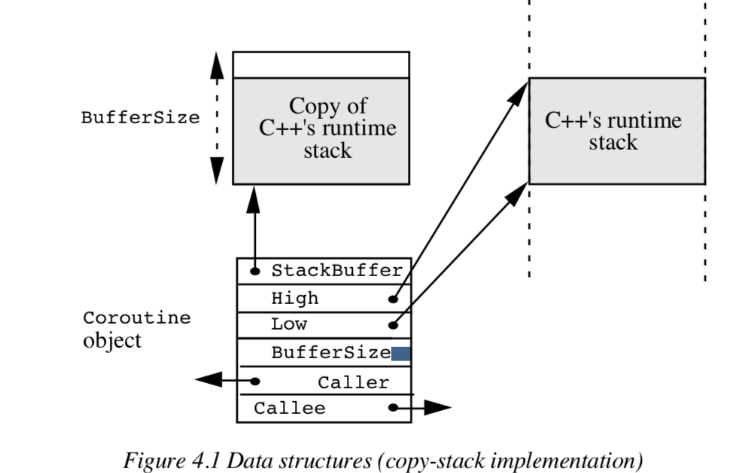
成员函数Enter执行上下文切换。调用C->Enter(),其中C指向一个Coroutine对象,挂起当前正在运行的Coroutine、Current和恢复Coroutine C。运行时堆栈保存在当前的堆栈缓冲区中,C的堆栈缓冲区复制到运行时堆栈中。
函数Enter的代码如下所示。
void Coroutine::Enter() {
if (!Terminated(Current)) {
Current->StoreStack();
if (setjmp(Current->Environment))
return;
}
Current = this;
if (StackBuffer) {
Routine();
delete Current->StackBuffer;
Current->StackBuffer = 0;
Detach();
}
RestoreStack();
}
辅助函数StoreStack用于保存运行时堆栈。它的实现如下所示。
void Coroutine::StoreStack() {
if (!Low) {
if (!StackBottom)
Error("StackBottom is not initialized");
Low = High = StackBottom;
}
char X;
if (&X > StackBottom)
High = &X;
else
Low = &X;
if (High - Low > BufferSize) {
delete StackBuffer;
BufferSize = High - Low;
if (!(StackBuffer = new char[BufferSize]))
Error("No more space available");
}
memcpy(StackBuffer, Low, High - Low);
}
首先,该函数计算运行时堆栈的边界(高低)。假设运行时堆栈的底部已经初始化(通过宏排序)。接下来,如果需要,它将分配一个缓冲区StackBuffer来保存运行时堆栈的副本。最后,将运行时堆栈复制到这个缓冲区。
注意,该函数考虑到运行时堆栈可能在某些平台上增长,而在其他平台上下降。
为了恢复协同程序的状态,使用了辅助函数RestoreStack。这个函数的代码如下所示。
void Coroutine::RestoreStack() {
char X;
if (&X >= Low && &X <= High)
RestoreStack();
Current = this;
memcpy(Low, StackBuffer, High - Low);
longjmp(Current->Environment, 1);
}
该函数将堆栈缓冲区的内容复制到运行时堆栈,并跳转到保存在缓冲区环境中的执行位置。但是,首先,只要当前顶层地址在运行时堆栈的保存地址范围内,该函数就会递归地调用自身。这可以防止恢复后的堆栈被后续的longjmp调用破坏。
实现了函数Enter后,很容易实现用户函数Resume、Call和Detach。它们的实现(不包括错误处理)如下所示。
Resume(Coroutine *Next) {
while (Next->Callee)
Next = Next->Callee;
Next->Enter();
}
void Call(Coroutine *Next) {
Current->Callee = Next;
Next->Caller void = Current;
while (Next->Callee)
Next = Next->Callee;
Next->Enter();
}
void Detach() {
Coroutine *Next = Current->Caller;
if (Next)
Current->Caller = Next->Callee = 0;
else {
Next = &Main;
while (Next->Callee)
Next = Next->Callee;
}
Next->Enter();
}
这个版本的协同程序库的完整程序代码可以在附录B中找到。
该实现的原理与作者在实现C语言[8]中的回溯编程库时使用的原理相同。实际上,后一个库可以很容易地通过协程库实现(参见第7节)。
4.2 栈共享实现
这个实现比前一个更复杂。第一次由Kofoed[10]描述的,基本思想是让所有协同程序堆栈共享c++的运行时堆栈。
运行时堆栈被划分为大小不同的连续区域。区域要么未使用,要么包含协同程序堆栈。递归函数调用用于结束堆栈并标记分配的区域。
每个区域都包含一个称为任务的控制块,它描述了区域的属性,例如它的大小以及是否在使用它。
类协程具有以下接口。
class Coroutine {
friend void Resume(Coroutine *);
friend void Call(Coroutine *);
friend void Detach();
friend void InitSequencing(size_t main_stack_size
= DEFAULT_STACK_SIZE);
protected:
Coroutine(size_t stack_size = DEFAULT_STACK_SIZE);
virtual void Routine() = 0;
private:
void Enter();
void Eat();
Task *MyTask;
size_t StackSize;
int Ready, Terminated;
Coroutine *Caller, *Callee;
};
类的数据成员具有以下含义。
MyTask:指向控制块的指针。
StackSize:堆栈的最大区域大小(以字节度量)。
Ready:表示协调程序是否准备好运行其例程。
Terminated:表示协调程序是否已终止其例程。
Caller,Callee:附加关系链接
结构Task如下所示。
struct Task {
Coroutine *MyCoroutine;
jmp_buf jmpb;
int used;
size_t size;
struct Task *pred, *suc;
struct Task *prev, *next;
};
类的数据成员具有以下含义。
MyCoroutine:指向所有者协程的指针
jmpb:由setjmp保存的环境
used:任务是否已经在使用
size:相关区域的大小(以字节为单位)
pred, suc:未使用任务的双链表中的“前置”和“后继者”
prev, next:指向两个相邻的任务
图4.2说明了数据结构。
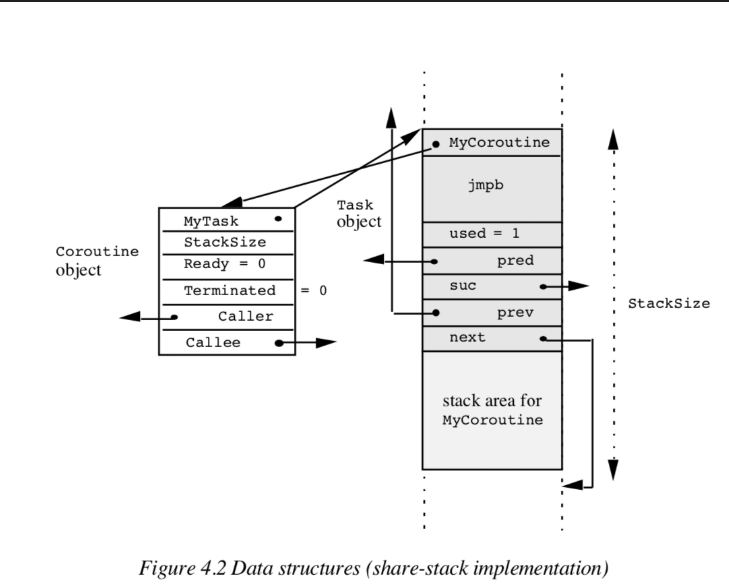
任务是在c++的运行时堆栈中分配的控制块。
通过调用函数InitSequencing来初始化程序。这个函数使用setjmp保存当前状态,并递归地调用一个函数Eat,直到它使用了足够多的c++运行时堆栈来容纳与主程序对应的堆栈。之后,该函数将当前状态与剩余空闲区域的大小一起保存在一个本地控制块中,将该区域标记为“空闲”,并使用longjmp跳转到先前保存的状态。这个控制块是为新的协同程序堆栈分配空间的潜在起点。
当不再需要堆栈时(因为相应的协程终止),控制块被标记为“free”,并可能与前一个或后一个free块合并(分别由prev和next引用)。
该实现与Kofoed的任务库实现非常相似(详细信息请参阅[10])。不过,也做了一些调整。
首先,协同程序库提供用户定义的协同程序之间的交替,而任务库提供由预定义的循环算法确定的交替。
其次,为了加快对可能的空闲块合并的搜索,相邻块的单链表被双链表代替。
第三,在程序初始化时,用户不需要提供整个堆栈区域的大小(只需提供主程序所需的堆栈区域的大小)。
关于协同程序库的共享堆栈实现的完整列表可以在附录C中找到。
4.3 比较两种实现
这两种实现中的哪一种是首选的?这个问题没有简单的答案。每种实现都有优点和缺点。
下面根据一系列标准对这两个实现进行评估。
4.3.1 易用性
这两种实现看起来都很容易使用。
复制堆栈实现的一个优点是,用户不需要为协同程序的堆栈大小操心。
相反,共享堆栈实现需要指定每个协同程序的最大堆栈大小。在复制堆栈方法的实际实现中,这个缺点已经有所减少。如果用户忽略了规范,则使用默认大小(10,000字节)。
4.3.2 效率
对于某些应用程序,复制堆栈实现可能会导致大量的复制。
通常,当库的拷贝堆栈版本被共享堆栈版本替换时,用于上下文切换的时间会减少。在具有许多上下文切换和/或大型堆栈的应用程序中,这种速度上的提高可能很重要。
在第6节中,将这些实现与它们在仿真应用程序中的效率进行了比较。
4.3.3 使用上的限制
复制堆栈实现导致回溯。在恢复协调程序时,堆栈将在协调程序挂起的最后时刻重新建立到其内容。这意味着自动变量(即,则堆栈上的变量)将其值恢复。暂停和恢复之间的任何更改均无效。此外,当自动对象由于控制开关而移动时,指向该对象的指针不再有效。
因此,共享变量在拷贝堆栈实现中不应该是自动的。它们应该是全局的或静态的。
此限制不适用于共享堆栈实现。
然而,这个限制通常并不重要。实际上,如第7节所示,复制堆栈实现的回溯特性可用于编写将协程查询与回溯结合使用的应用程序。
4.3.4 鲁棒性
共享堆栈实现没有检查堆栈溢出。如果用户指定的堆栈大小太小,程序将崩溃,或者更糟的是,在没有任何通知的情况下产生无意义的结果。
内存使用
在共享堆栈实现中,指定的最大堆栈大小是在协程启动时确定的。如果这个上限太大,就会使用大量不必要的内存。这在模拟应用中尤其重要,因为在模拟应用中,通常有许多同时协同程序以准并行的方式运行。
4.3.6 可维护性
复制堆栈实现似乎是最容易理解的,因此也是最容易维护的。
4.3.7 可移植性
这两种实现都是可移植的。在撰写本文时,它们都已经安装并成功测试了编译器,这些编译器分别安装在Macintosh、IBM PC和Sun SPARC上。